| # | Model | Size | Frames | Basic Tier | Advanced Tier | Real Cases | Overall (/100) |
| 1 | Gemini-3-Pro 🥇 | - | - | 63.6 | 68.2 | 68.0 | 66.4 |
| 2 | Gemini-2.5-Pro 🥈 | - | - | 65.4 | 66.4 | 44.8 | 64.6 |
| 3 | Doubao-Seed-2.0-lite🥉 | - | 1fps | 53.2 | 62.1 | 35.5 | 57.3 |
| 4 | MiMo-V2-Omni | - | 1fps | 53.6 | 55.2 | 41.0 | 53.8 |
| 5 | Qwen3.5-Omni-Plus | - | 1fps | 41.6 | 57.8 | 50.6 | 51.6 |
| 6 | Qwen3-Omni-Instruct | 30B-A3B | 1fps | 46.4 | 53.8 | 53.8 | 51.2 |
| 7 | MiniCPM-o-4.5 | 9B | 1fps | 44.6 | 47.8 | 37.8 | 46.0 |
| 8 | Baichuan-Omni-1.5 | 7B | 32 | 45.0 | 41.8 | 44.8 | 43.2 |
| 9 | Qwen2.5-Omni | 7B | 1fps | 37.0 | 46.6 | 45.2 | 43.2 |
| 10 | MiniCPM-o-2.6 | 8B | 1fps | 41.8 | 40.2 | 31.2 | 40.2 |
| 11 | VITA-1.5 | 7B | 4 | 24.6 | 25.8 | 14.6 | 24.6 |
Introduction
Recent advances in Omni-LLMs are paving the way for real-time video assistant applications, where models constantly perceive the environment and guide users to achieve certain goals through multi-turn conversations. However, evaluations under these assistant-style interaction scenarios are still challenging. OmniAssistBench aims at addressing this challenge by proposing an annotation pipeline which allows annotators to build test samples from existing Internet videos.
Why evaluation is challenging?
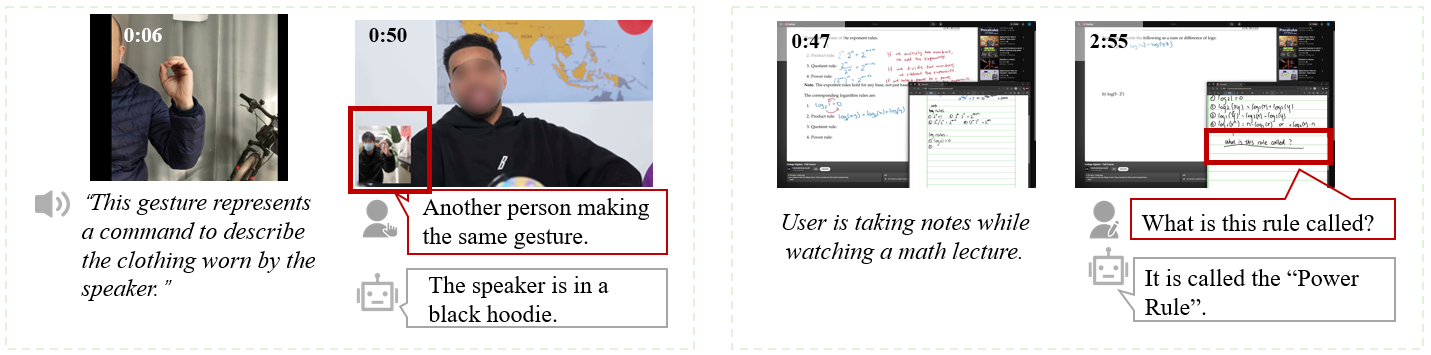
In traditional video understanding evaluation, the model's answer would not change the content of the test video. However, during interaction with assistant models, users will do what the model suggests. This means that the model's unpredictable response dynamically changes the subsequent video contents, which static offline datasets cannot accommodate.
How to address this challenge?
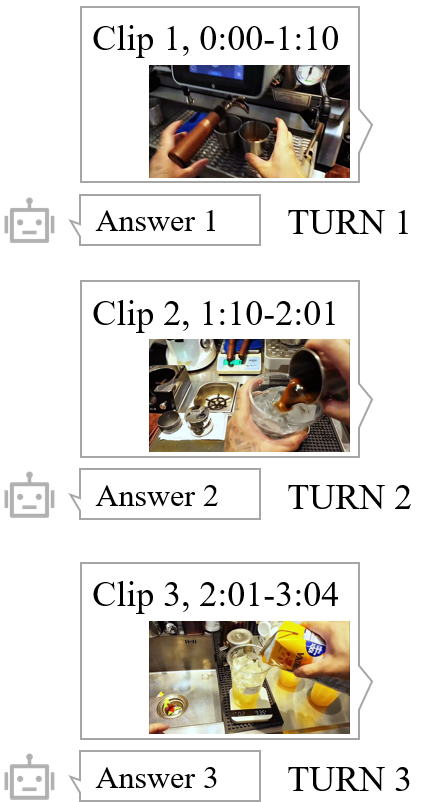
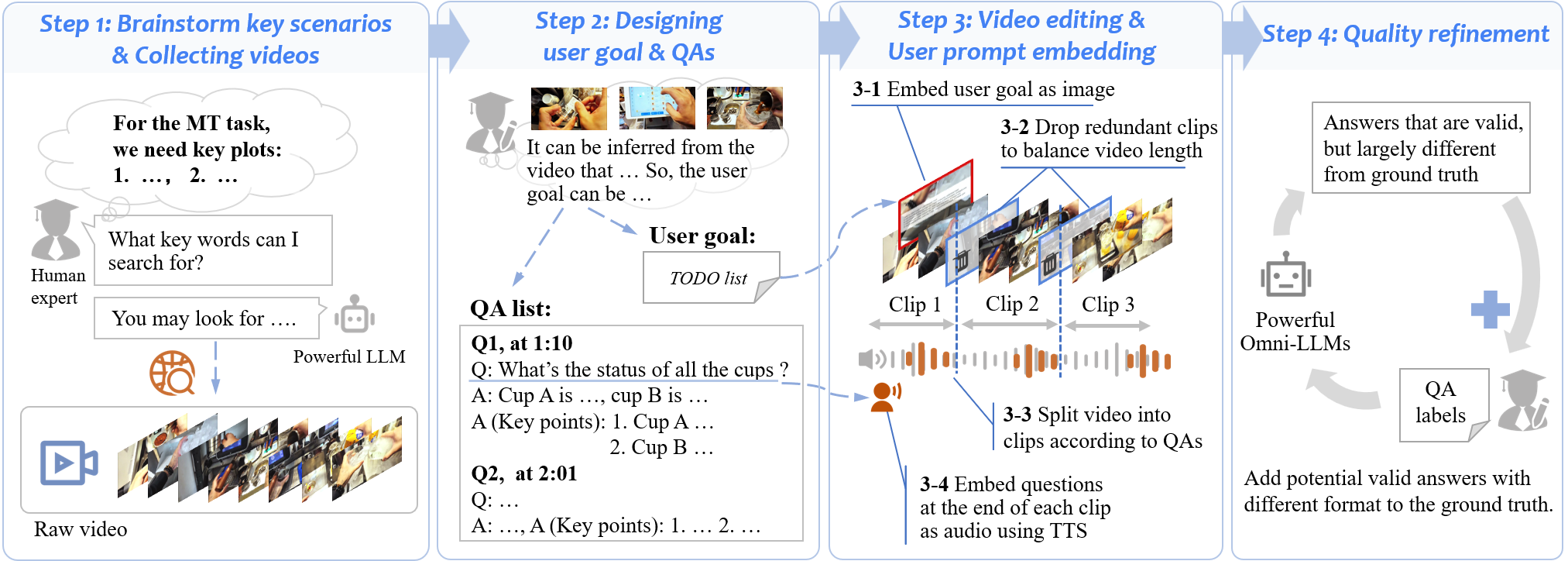
During annotation, experts first filter for videos with certain plots and deduce prior knowledge from the video content to enforce a fixed interaction path.
Based on the paths, experts then design detailed interaction turns and edit the videos accordingly to build human-assistant interaction recordings.
Based on the paths, experts then design detailed interaction turns and edit the videos accordingly to build human-assistant interaction recordings.
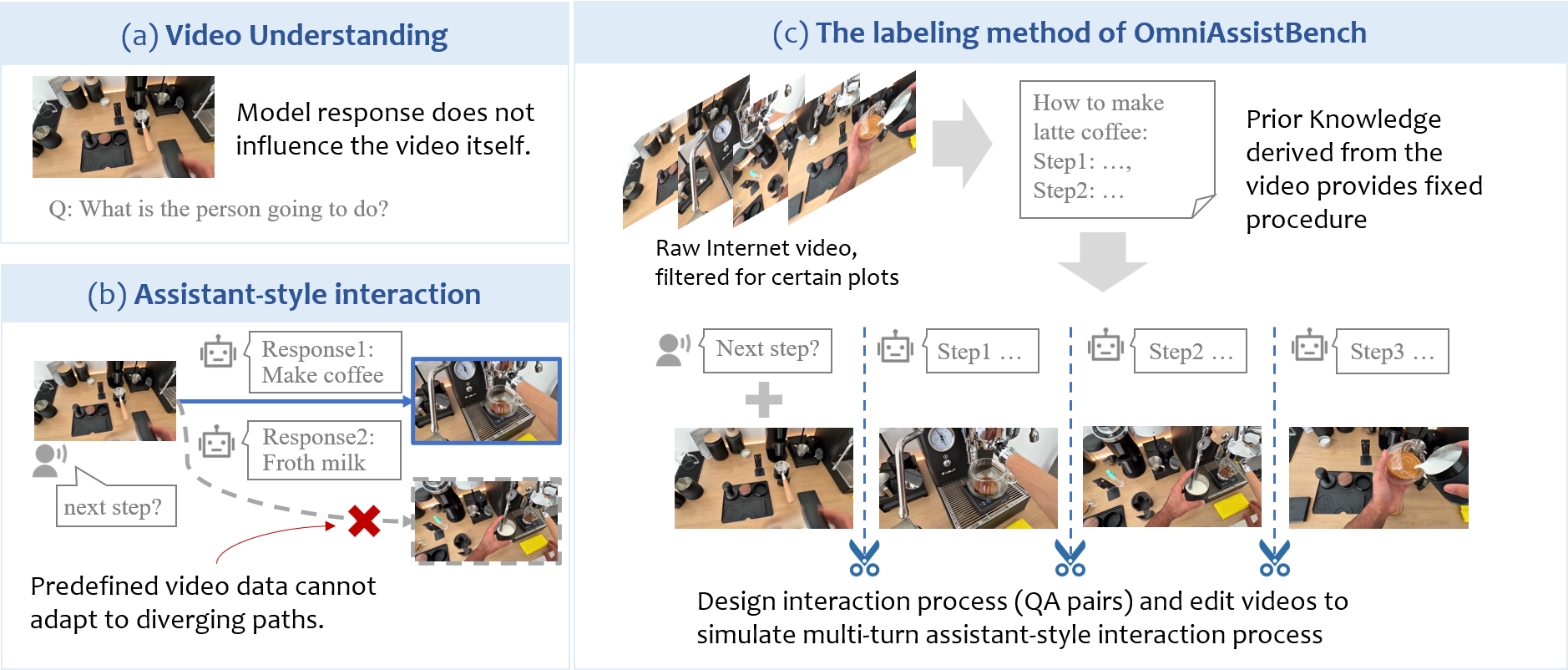
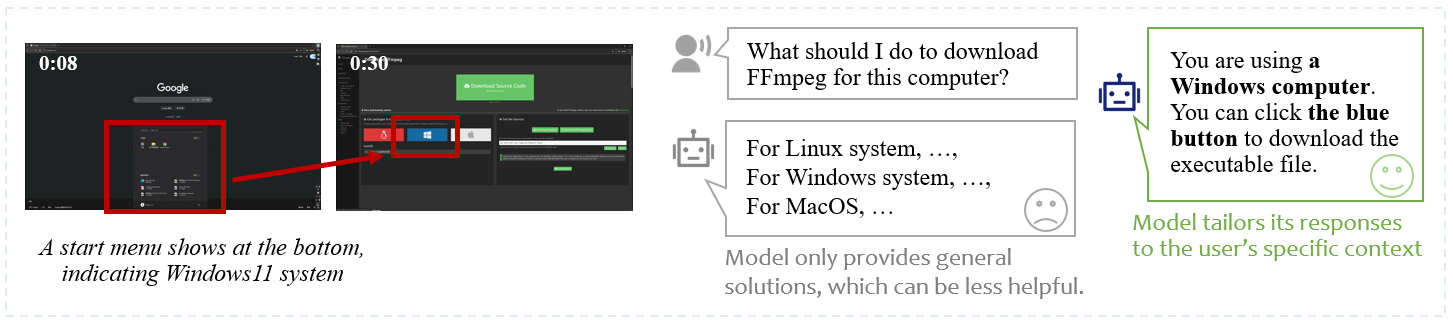
Assistant models may guide the user to achieve one goal through different paths (e.g., both Response 1 and Response 2 shown in figure (b) are valid, but test data only contains the consequent video of Response 1.)
We propose an annotation pipeline to address this problem of path diversity.
OmniAssistBench is highly challenging. According to our scoring rubrics, even state-of-the-art commercial Omni-LLMs only provide partially correct answers, indicating that there is substantial room for improvement before Omni-LLMs can become reliable real-world assistants.